ニュース
- ニュース
Share
【論文紹介】URLNet: 深層学習による悪意ある URL の検出手法
こんにちは。CSC で機械学習エンジニアを務める佐々木です。
論文紹介シリーズと称して、本記事では機械学習とサイバーセキュリティに関連した論文の紹介をしていきます。
AI によるルール自動運用最適化技術 WRAO や Web 攻撃検知技術 Cyneural の研究開発に従事してきた経験から、”サイバーセキュリティ” というドメイン特有の知見を交えつつ、内容を解説していきます。
今回紹介する提案手法である URLNet では、DeepLearning を用いて悪意のある URL を検出する試みが行われています。技術としては CNN を使用しています。CNN というと画像処理のタスクでおなじみですが、自然言語処理に使用しても従来の機械学習手法より高い精度が得られるということで、近年 NLP 界隈で注目されています。
本論文は特に自然言語処のタスクに CNN を適用する際の前処理手法に関して詳しく記述されているのでおすすめです。
# 概要
—————————————————–
CNN に文字単位(character-level)と単語単位(word-level)でベクトル化した特徴量を埋め込む事により、悪意のある URL の検出を試みます。本論文では文字、単語、文字 + 単語 パターンで学習を行った場合の精度を比較しています。その結果、従来の手法 (SVM) を用いたモデルよりも高い精度が得られたとのことです。
# 従来手法の課題
—————————————————–
従来手法の一例として、`Bag-of-word` の課題点が紹介されています。`Bag-of-word` を用いた場合に生じる不都合としては、主に以下のような項目が挙げられます。
– 単語の意味や、並び順が降所されない
`Bag-of-word` ではトークンの出現回数のみの情報しか保持していないので、各トークンの出現順については考慮されません。しかしながら、攻撃検知の現場ではトークンの出現順序が重要な意味を持ちます。
なぜサイバー攻撃ではトークンの順序が重要なのか、この点を理解するために SQL Injection の例を見てみましょう。例えば SQLInjection の攻撃手法の 1つとして、コメントアウトを挿入するという手口があります。
“`
SELECT * FROM members= ‘{variable}’ AND password= ‘{password}’
“`
という SQL があったとき、変数 `valiable` に `admin’–` を入力すると…?
“`
SELECT * FROM members= ‘admin’–‘ AND password= ‘{password}’
“`
となり、`–` 以降はコメントとして処理されるため `password` に何を入れてもこの SQL は成立し、admin の情報を取得できる訳です。
ここで先ほど攻撃として入力した値を振り返ってみましょう。`admin’–` がもしも `–‘admin` という並びであるとどうなるでしょうか。この SQL 文は Syntax Error となり刺さりません。このようにサイバーセキュリティのドメインにおいては、「攻撃を成立させるためにはある特定の並びでなければならない」というケースが多々あるのです。
– 未知のパターンに対応できない
`Bag-of-word` モデルでは、学習時にデータセットに存在しなかった単語に関しては何の情報も学ばないので、未知の単語やパターンを含む URL の検出に不向きです。
URLNet の論文では以上のような課題点を解決すべく、深層学習を用いた手法が紹介されます。
# 手法
—————————————————–
本論文の提案手法の要点をまとめると、CNN にデータを入れる前の前処理手法に関する議論が行われています。ここで提案されている前処理手法は2種類。URL を文字単位でベクトル化する手法と、単語単位でベクトル化する手法です。それぞれ見ていきましょう。
## Character-level Embeddings
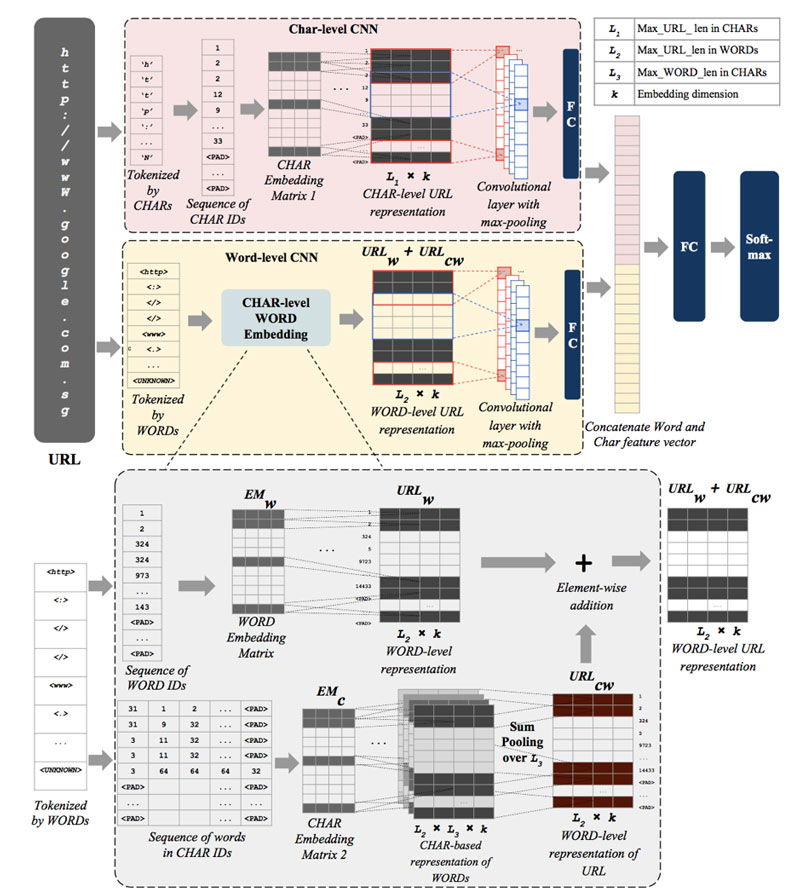
`Character-level Embeddings` では URL 中に含まれるアルファベット、数字、記号をそれぞれ 32次元のベクトルにします。ベクトルの値はランダムで初期化し、学習によって最適な値に更新します。URL 1つあたりの文字数は200に統一しています。このとき、200文字未満の URL はパディングし、200文字以上のものは先頭から200文字のみを使用します。各 URL の文字数が 200, 各文字のベクトルが 32次元なので、1つの URL は 200 * 32 の行列で表現されます。URL を表現した行列に対し、32 * h (h=3,4,5,6) の Filter を stride させることで 3~6 文字分の連続したパターンを学習させています。
Character-level の Embedding では文字単位で学習するので推論時に未知の単語が出てきても対応できるという強みがあります。一方で、長いシーケンスのパターンを学習できないという欠点もあります。この問題に対処するため、`Word-level` での Embedding 手法が提案されています。
## Word-level Embeddings
### Word Embeddings
`Word-level` の Embeddings では、まず最初にトレーニングセット中に含まれるすべてのユニークな単語の集合を定義します。各単語は `.`, `/` などの特定の文字で区切られた文字列と定義します。各単語は 32次元のベクトルと定義し、ランダムな値で初期化し学習によって最適化します。各単語のベクトルが 32次元なので、単語数 M の URL は M * 32 の行列として表現されます。この行列に対し 32 * h (h=3,4,5,6) の Filter によって畳み込み演算を行うことで、単語 3~6 個分の連続したパターンに対応した特徴を学習します。
`Word-level` の Embeddings では複数の単語で構成されるような、比較的長いパターンの特徴を学習できるという利点っがあります。一方で学習時に存在しなかった未知の単語に対して弱いという欠点があります。この点を改善すべく、各単語をさらに文字毎にベクトル化する `Word-level character Embeddings` が提唱されています。
### Word-level character embeddings
`Word-level character Embeddings` では、`Word-level` Embedding の単語部分に使用されている文字を改めてベクトル化し、各単語ごとに `Character-level` の行列を作成します。
### モデル
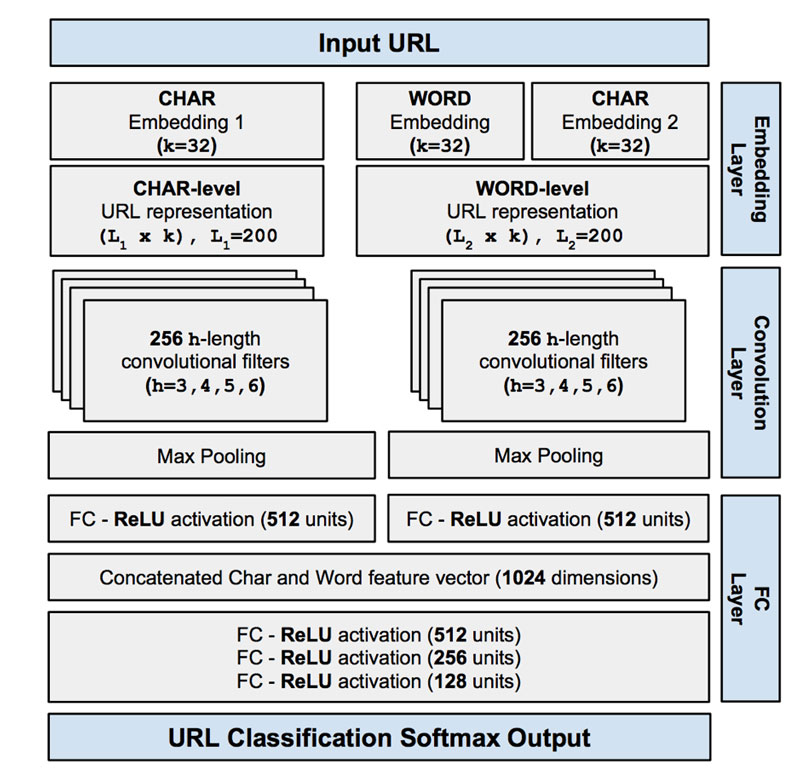
`Character-level`, `Word-level`, `Word-level-character` の各 Embeddings には一長一短があります。そのため、どれか 1つを用いた場合より、全ての Embeddings から来る出力を統合することで互いの欠点が補完され、精度が高まるのではないかと提唱されています。すべてを結合したモデルは次の図1のようになります。
# 結果
—————————————————–
## データ
トレーニングおよび性能の検証に使用するデータとしては、`VirusTotal` から取得した 3ヶ月分の URL を使用しています。レコード数は学習に 500万、テストに1000万件となっています。
## 比較対象
URLNet との比較対象として、DeepLearning を使用しない従来手法として、Support Vector Machine を 5種類の Embedding でトレーニングした場合の結果が示されています。ここで用いられている Embedding は Whole URL BoW, UTC, PSB, Character Triangles と、これらを全て同時に適用したもの (Combined) です。`Whole URL BoW` はトレーニングデータセット中の URL から得られた `Bag-of-Word` です。
また、URLNet の評価として 1.Character-level 単体、2.Word-level 単体、3.Character-level + Word-level (Full) 併用の3パターンで性能を比較しています。
## 結果
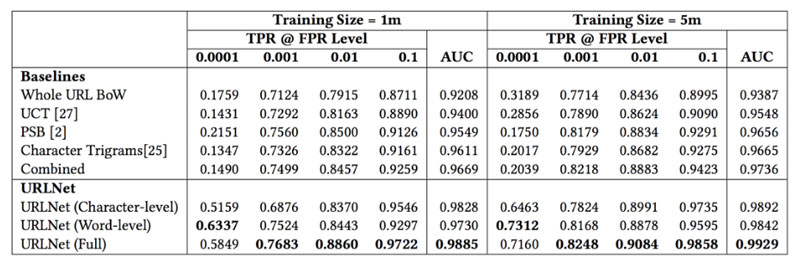
URLNet では 3種類どの方式においても従来の機械学習 (SVM) と比較して優位な結果が得られています。従来の機械学習手法で用いられている UTC, PSB, Character Triangles はセキュリティの専門家によって設計されたものを使用していますが、DeepLearning を用いた URLNet はそれを上回る結果を出しています。URLNet における特徴量の設計 (Feature Extraction) についておさらいしてみますと、`Character-level` では各文字をそのままベクトル化するだけなのでほぼ人ではかかっていません。また、`Word-level` に関しても URL の文字列を機械的に分割しているだけなのでほぼ自動です。特徴量設計に人手をかけることなく従来手法を上回る結果を叩き出しているのですから、深層学習がいかにサイバーセキュリティのドメインにおいても有用であるかということが分かるかと思います。
また、URLNet どうしの比較でも `Character-level` と `Word-level` 双方を用いた場合にそれぞれを単体で用いた場合よりも高い精度が実現できています。
# まとめ
—————————————————–
・CNN を用いた NLP の分類問題では、文字列単位 + 単語単位双方でベクトル化を行うことで、互いの弱点を補完できる
・深層学習を用いることで、セキュリティドメインの専門知識を用いた特徴量設計が不要になる
サイバーセキュリティの界隈では専門家の不足が問題点として度々話題に上がります。
こうした事情を考えると、セキュリティドメインの専門知識がなくてもある程度の精度が得られる、という深層学習の利点は今後ますます注目されていくのではないでしょうか。
# 参考文献
—————————————————–
https://arxiv.org/abs/1802.03162
# 著者
—————————————————–
佐々木 友輔
AI Engineer/ Researcher