ニュース
- ニュース
Share
Web アプリケーションのサイバーセキュリティにおける AI について - AI in CyberSecurity for Web Applications –
AI in CyberSecurity for Web Applications
These words have been a nightmare for many companies around the world, and the question that arises frequently is: Can AI & Cybersecurity work together? Obviously, the answer is YES!
So, the main purpose of this blog is to understand why we think that not only these two can work together, but we believe that AI will push forward the limits of cybersecurity beyond imagination.
In this blog, we will explain the concept of AI as a tool in any framework, then we will briefly explain how the cybersecurity for web applications is used to defend against malicious attackers.
Since the Cybersecurity for web applications is a wide topic, in this blog, we will just focus on data processing requests, i.e. attacks on layer 7 (Application Layer) of the OSI model.
In the end, we will give a few examples of the techniques that have been developed in other fields with high accuracy.
What means AI?

What is this AI? Why all the businesses out there are trying to implement it?
In the actual world, where everything is connected and the flow of data is increasing day by day, how we can get real knowledge from this data is becoming a complicated task.
Here is where AI will play a fundamental role.
Thanks to the actual computational power, we can deal with huge amounts of data that a normal human brain cannot even imagine. In these heaps of data, AI can find hidden structures and give us some useful data that our modest brain can handle.
Now, all of this sounds wonderful. But, achieving this goal would be a complicated task.
This is because real data usually have a complicated structure, so just a simple linear separation will not be enough. That’s why a tool which can process more complicated structure is required. This tool is AI, where the data can be treated in a non-linear way.
To be able to retrieve valuable information, different approaches and algorithms were invented.
There are lots of different types of AI algorithms out there, and it is a herculean task to know all of them. That is why we need to understand our data and its interaction, then find the AI algorithm which fits the best with our task.
Cybersecurity for Web Applications
We have already got a wide view of what an AI can do. Now, we need to focus on understanding the data in a web application for cybersecurity.
The data in web applications is getting harder and harder to understand due to the connectivity between applications and any other internet service. On the other hand, each web application is using different framework to interact with the customers. All of this makes it a huge challenge for cybersecurity providers.
But at least we know that the application interacting with each user is the same in any framework, and as the user sends a request (log), the web application responds to it depending on the request. This request is usually a string of characters whose structure is known (“GET /path1/path2/file.php?var1=value&var2=value HTTP”).
Nowadays, a good way to defend our web applications is by observing this request (a string of characters) and check if it has some known pattern. This is known as Security Information and Event Management, SIEM. These patterns are built by cybersecurity experts from known attacks. However, the problem is that the list of these patterns is increasing and sometimes it is not enough to block the new kind of attacks, and that is why a new tool is needed to bring into play, AI.
As we mentioned before, this interaction is a string of characters, so it is a map of different nodes that are connected with another node or itself once per time slice, that is why we can think the interaction of any user is just a unidirectional graph. At the same time, this interaction will have some information that we should not consider and erasing that part of the graph will increase the performance of our algorithm.
Matching both worlds:
Now that we have a basic understanding of AI and about cybersecurity for web applications, we will see how this AI will be one of the tools for the future of cybersecurity.
As we know, just trying to check the amount of different AI tools available can make anyone feel dizzy, we will try to mention two different approaches which are most commonly used. For these approaches, we only explain the concept of how data is transformed, but we will not explain which architecture works better: FCN, CNN, RNN’s… Unfortunately, this choice can only be made by trial & error method and it depends strongly on your algorithm and data.
So, let’s have a look:
Labeling algorithm:
The first one is a straightforward AI tool, labeling neural network. This algorithm has a good performance but has different known issues:
-It’s like a black box:
This kind of procedure will only give us the possibility of being malicious or not. So, getting the reason why a URL request was rejected is a challenging problem.
-It is easy to fool:
Maybe because it was the first NN algorithm that works properly, nowadays we know that there are several ways to fool this algorithm: adversarial patch, adversarial machine learning, etc.
For example, the adversarial patch can be used: If in our MALICIOUS request we insert some BENIGN string, this can transform the request as a BENIGN request. This example was already studied with unlucky results for the detection makers.
https://skylightcyber.com/2019/07/18/cylance-i-kill-you/
-What should we do if it fails? Train again!!
This will be a huge problem in our case because we cannot leave our web application without any WAF and it will cost time and money to the company.
-We need a normalized data:
It is obvious that to train this data, we need reliable data and on the other hand sometimes we do not have enough malicious data in a web application.
So, we can imagine why “labeling algorithm” is not the best approach for our framework. However, it may work as an initial tool.
Neural network embedding
Coming back to our previous discussion, we know that our framework is a unidirectional graph. So, we should use an algorithm that uses the concept of a graph.
At the same time, this is not a straightforward task due to some of the issues, which we will explain later. But we should mention some important aspect of this algorithm:
-We will be able to use some non-supervised algorithm.
-The algorithm can maintain the structure of the data better.
-If something gets wrong, we do not need to retrain our algorithm. (We can block the area where the problem occurs)
-It is harder to fool, but not impossible!!: As we can see right now, this approach can play in more dimensions than two (ANOMALOUS, NON-ANOMALOUS), so it will be more difficult to fool this algorithm with the usual tools. The fight against the bad guys never ends!
 The idea of this algorithm is to be able to do an embedding of the graph in a lower dimension.
The idea of this algorithm is to be able to do an embedding of the graph in a lower dimension.
For this procedure, we need to define the concept of similarity (distance) between each graph. In other words, this procedure is called “learning manifold”.
As an example, we can use these ideas for MNIST challenge and get an idea of the topology of MNIST data by using embedding and reduction techniques.
As we can see in this figure on the left, this technique can generate different sectors depending if the graph is a 0,1, 2, 3, …,9.
Now, if a new graph appears and it is inside the region defined as 4, we could say the graph is a 4.
This looks wonderful. But to achieve this, we need to go through several steps, which we have skipped at the time, but are necessary to get the results.
The first step to consider is similarity (distance). In the MNIST challenge, the definition of distance is straightforward, but in our framework, this definition is not that easy. So, different definitions must be understood to use the most convenient one. This similarity (distance) definition brings us the concept of the lowest dimension, where it is the lowest dimension where this learning manifold lives. This is simple if we just have one DATA in our mind, but in the case of cybersecurity, this lower dimension depends strongly on the web application we are treating. So, an approach that gives us this dimension is needed.
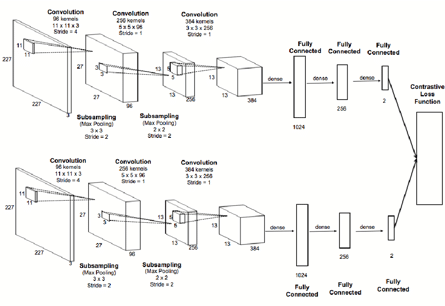 If we are lucky and are able to find a marvelous distance, the next step is quite straightforward because the study of doing this is wide and we can say that the best approach is Similarity SIAMESE neural network (as shown in the figure on the left). Although this is a straightforward step, the point of deciding which neural network will be crucial for our results.
If we are lucky and are able to find a marvelous distance, the next step is quite straightforward because the study of doing this is wide and we can say that the best approach is Similarity SIAMESE neural network (as shown in the figure on the left). Although this is a straightforward step, the point of deciding which neural network will be crucial for our results.
Once we have our beautiful learning manifold, we can proceed to the clustering procedure. In this procedure, it is hard to say which one works better and a trial and error system is the only feasible option.
The next step, last but not least, is dimensional reduction.
Now, our experience is telling us that the dimensions of a learning manifold might be quite large, and therefore, the process of evaluating a new graph (string request) will not be efficient. That is why, we think, a dimensional reduction procedure will improve this efficiency. This algorithm like the others is not unique and there are plenty of them, but the good news here is that we do not need to define another concept, like similarity, the algorithm by itself will find the optimum reduction keeping the topology.
Therefore, if we could achieve this process, congratulations! We can have a wonderful AI algorithm to use for cybersecurity for web applications.
Conclusion
We can see that this is a challenging task. But with the actual knowledge, we will be able to deploy a nice tool for our goal.
In this blog, we explained just two algorithms but different algorithms focusing on different features or mixing both algorithms. The thing in AI is that we can never conclude that one algorithm is better than the other, and therefore being able to deploy several algorithms will be essential for a realistic AI cyber security system, due to the necessity of high accuracy in the results. A mistake in the implementation can cause too much damage.
We hope you have learned about the issues in AI for cybersecurity that have to be managed. Other algorithms can also be deployed, but until now this is a good summary of what we can do nowadays using AI.
At the same time, there is another topic to speak about… how to process all the data we have, to train our algorithm properly, this is a large topic too which we’ll try to elaborate next time.
Thanks,
PhD Sergio Calle Jimenez
AI Engineer